Neo4j图形化数据库
Neo4j - 需要图形数据库
图数据库用于存储更多的连接数据。 如果我们使用 RDBMS 数据库来存储更多连接的数据,那么它们不能提供用于遍历大量数据的适当性能。 在这些情况下,Graph Database 提高了应用程序性能。
什么是连接数据? 以及这些应用程序如何与某些实时应用程序存储数据。
方案1:Google+
使用 Google+(GooglePlus)应用程序来了解现实世界中 Graph
数据库的需求。 观察下面的图表。 在这里,我们用圆圈表示了
Google+应用个人资料。 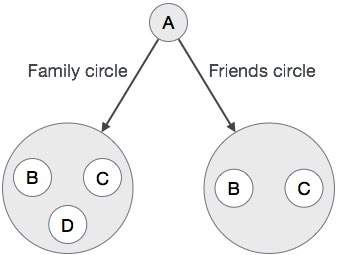 在上图中,轮廓“A”具有圆圈以连接到其他轮廓:家庭圈(B,C,D)和朋友圈(B,C)。
在上图中,轮廓“A”具有圆圈以连接到其他轮廓:家庭圈(B,C,D)和朋友圈(B,C)。
再次,如果我们打开配置文件“B”,我们可以观察以下连接的数据。 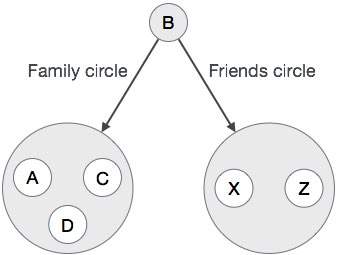 像这样,这些应用程序包含大量的结构化,半结构化和非结构化的连接数据。 在
RDBMS 数据库中表示这种非结构化连接数据并不容易。
像这样,这些应用程序包含大量的结构化,半结构化和非结构化的连接数据。 在
RDBMS 数据库中表示这种非结构化连接数据并不容易。
如果我们在 RDBMS 数据库中存储这种更多连接的数据,那么检索或遍历是非常困难和缓慢的。
所以要表示或存储这种更连接的数据,我们应该选择一个流行的图数据库。
图形DBMS非常容易地存储这种更多连接的数据。 它将每个配置文件数据作为节点存储在内部,它与相邻节点连接的节点,它们通过关系相互连接。
他们存储这种连接的数据与上面的图表中的相同,这样检索或遍历是非常容易和更快的。
方案2:Facebook
利用 Facebook 应用程序了解现实世界中 Graph 数据库的需求。  在上面的图中,Facebook
Profile“A”已经连接到他的朋友,喜欢他的一些朋友,发送消息给他的一些朋友,跟随他喜欢的一些名人。
在上面的图中,Facebook
Profile“A”已经连接到他的朋友,喜欢他的一些朋友,发送消息给他的一些朋友,跟随他喜欢的一些名人。
这意味着大量的连接数据配置文件A.如果我们打开其他配置文件,如配置文件B,我们将看到类似的大量的连接数据。
注-通过观察上述两个应用程序,它们有很多更多的连接数据。 它是非常容易存储和检索,这种更连接的数据与图形数据库。
[========]
Neo4j - CQL简介
CQL代表Cypher查询语言。 像Oracle数据库具有查询语言SQL,Neo4j具有CQL作为查询语言。
Neo4j CQL -
- 它是Neo4j图形数据库的查询语言。
- 它是一种声明性模式匹配语言
- 它遵循SQL语法。
- 它的语法是非常简单且人性化、可读的格式。
如Oracle SQL -
- Neo4j CQL 以命令来执行数据库操作。
- Neo4j CQL 支持多个子句像在哪里,顺序等,以非常简单的方式编写非常复杂的查询。
- NNeo4j CQL 支持一些功能,如字符串,Aggregation.In 加入他们,它还支持一些关系功能。
Neo4j CQL命令/条款
常用的Neo4j CQL命令/条款如下:
| S.NO | CQL命令/条 | 用法 |
|---|---|---|
| 1 | CREATE创建 | 创建节点,关系和属性 |
| 2 | MATCH匹配 | 检索有关节点,关系和属性数据 |
| 3 | RETURN返回 | 返回查询结果 |
| 4 | WHERE哪里 | 提供条件过滤检索数据 |
| 5 | DELETE删除 | 删除节点和关系 |
| 6 | REMOVE移除 | 删除节点和关系的属性 |
| 7 | ORDER BY以...排序 | 排序检索数据 |
| 8 | SET组 | 添加或更新标签 |
Neo4j CQL 函数
以下是常用的Neo4j CQL函数:
| S.NO | 定制列表功能 | 用法 |
|---|---|---|
| 1. | String字符串 | 它们用于使用String字面量。 |
| 2. | Aggregation聚合 | 它们用于对CQL查询结果执行一些聚合操作。 |
| 3. | Relationship关系 | 他们用于获取关系的细节,如startnode,endnode等。 |
后面的章节中详细讨论所有Neo4j CQL命令,子句和函数语法,用法和示例。
Neo4j CQL数据类型
这些数据类型与Java语言类似。 它们用于定义节点或关系的属性 Neo4j CQL支持以下数据类型:
| S.NO | 定制列表功能 | 用法 |
|---|---|---|
| 1. | boolean | 用于表示布尔文字:true,false。 |
| 2. | byte | 用于表示8位整数。 |
| 3. | short | 用于表示16位整数。 |
| 4. | int | 用于表示32位整数。 |
| 5. | long | 用于表示64位整数。 |
| 6. | float | 用于表示32位浮点数。 |
| 7. | double | 用于表示64位浮点数。 |
| 8. | char | 用于表示16位字符。 |
| 9. | String | 用于表示字符串。 |
Neo4j CQL - CREATE命令
Neo4j使用CQL- create命令
- 创建没有属性的节点
- 使用属性创建节点
- 在没有属性的节点质检创建关系
- 使用属性创建节点之间的关系
- 为节点和关系创建单个和多个标签
接下来将创建一个没有属性的节点:
Neo4j CQL创建一个没有属性的节点
create命令用于创建没有属性的节点,只是创建一个没有任何数据的节点。
CREATE命令语法
1 | CREATE ( <node-name>:<label-name>) |
语法说明
| 语法元素 | 描述 |
|---|---|
| CREATE | 是一个Neo4j CQL命令 |
| 是我们要创建的节点名称 | |
| 是一个节点标签名称 |
注意事项 -
1、Neo4j数据库服务器使用此将此节点详细信息存储在Database.As中作为Neo4j DBA或Developer,我们不能使用它来访问节点详细信息。
2、Neo4j数据库服务器创建一个作为内部节点名称的别名。作为Neo4j DBA或Developer,我们应该使用此标签名称来访问节点详细信息。
Neo4j CQL创建具有属性的节点
Neo4j CQL“CREATE”命令用于创建带有属性的节点。 它创建一个具有一些属性(键值对)的节点来存储数据。
CREATE命令语法:
1 | CREATE ( |
语法说明:
| 语法元素 | 描述 |
|---|---|
| 它是我们将要创建的节点名称。 | |
| 它是一个节点标签名称 | |
| ... | 属性是键值对。 定义将分配给创建节点的属性的名称 |
| ... | 属性是键值对。 定义将分配给创建节点的属性的值 |
例如:
此示例演示如何创建具有一些属性(deptno,dname,位置)的Dept节点。 按照下面给出的步骤 -
步骤1 - 打开Neo4j数据浏览器。
步骤2 - 在数据浏览器中的dollar提示符下键入以下命令。
1 | CREATE (dept:Dept { deptno:10,dname:"Accounting",location:"Hyderabad" }) |
这里dept是一个节点名 Dept是dept节点的标签名称 这里的属性名称是deptno,dname,location
属性值为10,"Accounting","Hyderabad"
正如我们讨论的,属性一个名称 - 值对。
Property = deptno:10
因为deptno是一个整数属性,所以我们没有使用单引号或双引号定义其值10。
由于dname和location是String类型属性,因此我们使用单引号或双引号定义其值。 注意 - 要定义字符串类型属性值,我们需要使用单引号或双引号。
Neo4j CQL - MATCH命令
Neo4j CQL MATCH 命令用于
- 从数据库获取有关节点和属性的数据
- 从数据库获取有关节点,关系和属性的数据
MATCH 命令语法:
1 | MATCH |
语法说明:
| 语法元素 | 描述 |
|---|---|
| 这是我们要创建一个节点名称。 | |
| 这是一个节点的标签名称 |
注意事项 -
Neo4j 数据库服务器使用此 将此节点详细信息存储在 Database.As 中作为 Neo4j DBA 或 Developer,我们不能使用它来访问节点详细信息。
Neo4j 数据库服务器创建一个 作为内部节点名称的别名。作为 Neo4j DBA 或 Developer,我们应该使用此标签名称来访问节点详细信息。 注意-我们不能单独使用 MATCH Command 从数据库检索数据。 如果我们单独使用它,那么我们将 InvalidSyntax 错误。
例如:
1 | MATCH (dept: Dept) |
这里 -
dept 是节点名称 Dept 是 emp 节点的标签名称
报错信息:Neo.ClientError.Statement.SyntaxError Query cannot conclude with MATCH (must be RETURN or an update clause) (line 1, column 1 (offset: 0)) "match(dept:Dept)" ^
使用match (n) return n
1 | # 查询Dept下的内容 |
Neo4j CQL - RETURN子句
Neo4j CQL RETURN子句用于 -
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
RETURN命令语法:
1 | RETURN |
语法说明:
| 语法元素 | 描述 |
|---|---|
| 它是我们将要创建的节点名称。 | |
| ... | 属性是键值对。 定义要分配给创建节点的属性的名称 |
我们不能单独使用RETURN子句。我们应该既MATCH使用或CREATE命令。
MATCH & RETURN匹配和返回
在Neo4j CQL中,我们不能单独使用MATCH或RETURN命令,因此我们应该合并这两个命令以从数据库检索数据。
Neo4j使用CQL MATCH + RETURN命令 -
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
MATCH RETURN命令语法:
1 | MATCH Command |
语法说明:
| 语法元素 | 描述 |
|---|---|
| MATCH命令 | 这是Neo4j CQL MATCH命令。 |
| RETURN命令 | 这是Neo4j CQL RETURN命令。 |
MATCH命令语法:
1 | MATCH |
语法说明:
| 语法元素 | 描述 |
|---|---|
| 它是我们将要创建的节点名称。 | |
| 它是一个节点标签名称 |
要点 -
- Neo4j数据库服务器使用此将此节点详细信息存储在Database.As中作为Neo4j DBA或Developer,我们不能使用它来访问节点详细信息。
- Neo4j数据库服务器创建一个作为内部节点名称的别名。作为Neo4j DBA或Developer,我们应该使用此标签名称来访问节点详细信息。
RETURN命令语法:
1 | RETURN |
语法说明:
| 语法元素 | 描述 |
|---|---|
| 它是我们将要创建的节点名称。 | |
| ... | 属性是键值对。 定义将分配给创建节点的属性的名称 |
例如: 本示例演示如何从数据库检索Dept节点的一些属性(deptno,dname)数据。
注-结点包含3个属性:deptno,dname,location。 然而在这个例子中,我们感兴趣的是只查看两个属性数据。 按照下面给出的步骤 -
步骤1 -打开Neo4j的数据浏览器。
步骤2 -在数据浏览器中的dollar提示符下键入以下命令。
1 | MATCH (dept: Dept) |
这里
- dept是节点名称
- Dept是一个节点标签名
- deptno是dept节点的属性名称
- dname是dept节点的属性名
如果观察到数据浏览器消息,它将显示有关两个属性的Dept节点的数据:deptno,dname。 它返回Neo4j数据库中可用的两个节点(行)。
例如: 此示例演示如何从数据库检索Dept节点的数据,而无需指定其属性。 注-结点包含3个属性:deptno,dname,location。 按照下面给出的步骤 -
步骤1 -打开Neo4j数据浏览器。
步骤2 -在数据浏览器中的dollar提示符下键入以下命令。
1 | MATCH (dept: Dept) |
这里dept是一个节点名
这里Dept是一个节点标签名
CREATE+MATCH+RETURN命令
在Neo4j CQL中,我们不能单独使用MATCH或RETURN命令,因此我们应该结合这两个命令从数据库检索数据。
演示如何使用属性和这两个节点之间的关系创建两个节点。
注-我们将创建两个节点:客户节点 (Customer) 和信用卡节点 (CreditCard)。
- 客户节点包含:ID,姓名,出生日期属性
- CreditCard节点包含:id,number,cvv,expiredate属性
- 客户与信用卡关系:DO_SHOPPING_WITH
- CreditCard到客户关系:ASSOCIATED_WITH
我们将在以下步骤中处理此示例: -
- 创建客户节点
- 创建CreditCard节点
- 观察先前创建的两个节点:Customer和CreditCard
- 创建客户和CreditCard节点之间的关系
- 查看新创建的关系详细信息
- 详细查看每个节点和关系属性 注-我们将在本章讨论前三个步骤。我们将在以后的章节中讨论其余的步骤
创建客户节点
1 | CREATE(e: Customer{id:"1001",name:"ABC",dob:"01/10/1982"}) |
这里 -
- e是节点名称
- 在这里Customer是节点标签名称
- id,name和dob是Customer节点的属性名称
创建CreditCard节点
1 | CREATE (cc:CreditCard{id:"5001",number:"1234567890",cvv:"888",expiredate:"20/17"}) |
这里cc是一个节点名
这里CreditCard是节点标签名称
id,number,cvv和expiredate是CreditCard节点的属性名称
观察节点
现在我们创建了两个节点:Customer和CreditCard
我们需要使用带有RETURN子句的Neo4j CQL MATCH命令查看这两个节点的详细信息
查看客户节点详细信息
步骤1 -打开Neo4j数据浏览器
步骤2 -在数据浏览器中的美元提示符下键入以下命令。
1 | MATCH (e:Customer) |
这里e是节点名
在这里Customer是节点标签名称
id,name和dob是Customer节点的属性名称
查看CreditCard节点详细信息
步骤1 -打开Neo4j数据浏览器
步骤2 -在数据浏览器中的dollar提示符下键入以下命令。
1 | MATCH (cc:CreditCard) |
这里cc是一个节点名
这里CreditCard是节点标签名称
id,number,cvv,expiredate是CreditCard节点的属性名称
关系基础
Neo4j图数据库遵循属性图模型来存储和管理其数据。
根据属性图模型,关系应该是定向的。 否则,Neo4j将抛出一个错误消息。
基于方向性,Neo4j关系被分为两种主要类型。
- 单向关系
- 双向关系 在以下场景中,我们可以使用Neo4j CQL CREATE命令来创建两个节点之间的关系。 这些情况适用于Uni和双向关系。
- 在两个现有节点之间创建无属性的关系
- 在两个现有节点之间创建有属性的关系
- 在两个新节点之间创建无属性的关系
- 在两个新节点之间创建有属性的关系
- 在具有WHERE子句的两个退出节点之间创建/不使用属性的关系 注意 -
我们将创建客户和CreditCard之间的关系,如下所示:
CREATE创建标签
Neo4j CQL创建节点标签
单个标签到节点
1 | CREATE (<node-name>:<label-name>) |
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | CREATE创建 | 它是一个Neo4j CQL关键字。 |
| 2 | <节点名称> | 它是一个节点的名称。 |
| 3 | <标签名称> | 这是一个节点的标签名称。 |
例如: 本示例演示如何为“GooglePlusProfile”节点创建单个标签。
1 | CREATE (google1:GooglePlusProfile) |
这里google1是一个节点名
GooglePlusProfile是google1node的标签名称
多个标签到节点
1 | CREATE (<node-name>:<label-name1>:<label-name2>.....:<label-namen>) |
例如: 本示例演示如何为“Cinema”节点创建多个标签名称。 我们的客户提供的多个标签名称:Cinema,Film,Movie,Picture。
1 | CREATE (m:Movie:Cinema:Film:Picture) |
这里m是一个节点名
Movie, Cinema, Film, Picture是m节点的多个标签名称
单个标签到关系
1 | CREATE (<node1-name>:<label1-name>)- |
语法说明
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | CREATE创建 | 它是一个Neo4J CQL关键字。 |
| 2 | <节点1名> | 它是From节点的名称。 |
| 3 | <节点2名> | 它是To节点的名称。 |
| 4 | 它是From节点的标签名称。 | |
| 5 | 它是To节点的标签名称。 | |
| 6 | <关系名称> | 它是一个关系的名称。 |
| 7 | <相关标签名称> | 它是一个关系的标签名称。 |
注意 -
- 我们应该使用colon(:)运算符来分隔节点名和标签名。
- 我们应该使用colon(:)运算符来分隔关系名称和关系标签名称。
- 我们应该使用colon(:)运算符将一个标签名称分隔到另一个标签名称。
- Neo4J数据库服务器使用此名称将此节点详细信息存储在Database.As中作为Neo4J DBA或开发人员,我们不能使用它来访问节点详细信息。
Neo4J Database Server创建一个标签名称作为内部节点名称的别名。作为Neo4J DBA或Developer,我们应该使用此标签名称来访问节点详细信息。
例如: 本示例演示如何为关系创建标签
步骤1 -打开Neo4J数据浏览器
步骤2 -在数据浏览器上键入以下命令
1 | CREATE (p1:Profile1)-[r1:LIKES]->(p2:Profile2) |
这里p1和profile1是节点名称和节点标签名称“From Node”
p2和Profile2是“To Node”的节点名称和节点标签名称
r1是关系名称
LIKES是一个关系标签名称
WHERE子句
像SQL一样,Neo4j CQL在CQL MATCH命令中提供了WHERE子句来过滤MATCH查询的结果。
简单WHERE子句语法
1 | WHERE <condition> |
复杂WHERE子句语法
1 | WHERE <condition> <boolean-operator> <condition> |
我们可以使用布尔运算符在同一命令上放置多个条件。 请参考下一节,了解Neo4j CQL中可用的布尔运算符。
语法:
1 | <property-name> <comparison-operator> <value> |
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | WHERE | 它是一个Neo4J CQL关键字。 |
| 2 | <属性名称> | 它是节点或关系的属性名称。 |
| 3 | <比较运算符> | 它是Neo4j CQL比较运算符之一。请参考下一节查看Neo4j CQL中可用的比较运算符。 |
| 4 | <值> | 它是一个字面值,如数字文字,字符串文字等。 |
Neo4j CQL中的布尔运算符
Neo4j支持以下布尔运算符在Neo4j CQL WHERE子句中使用以支持多个条件。
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | AND | 它是一个支持AND操作的Neo4j CQL关键字。 |
| 2 | OR | 它是一个Neo4j CQL关键字来支持OR操作。 |
| 3 | NOT | 它是一个Neo4j CQL关键字支持NOT操作。 |
| 4 | XOR | 它是一个支持XOR操作的Neo4j CQL关键字。 |
Neo4j CQL中的比较运算符
| S.No. | 布尔运算符 | 描述 |
|---|---|---|
| 1 | = | 它是Neo4j CQL“等于”运算符。 |
| 2 | <> | 它是一个Neo4j CQL“不等于”运算符。。 |
| 3 | < | 它是一个Neo4j CQL“小于”运算符。 |
| 4 | > | 它是一个Neo4j CQL“大于”运算符。 |
| 5 | > | 它是一个Neo4j CQL“小于或等于”运算符。 |
| 6 | > | 它是一个Neo4j CQL“大于或等于”运算符。 |
例如 此示例演示如何在MATCH Command中使用CQL WHERE子句根据员工名称检索员工详细信息。
1 | MATCH (emp:Employee) |
例如: 此示例演示如何在MATCH Command中的CQL WHERE子句中使用多个条件与布尔运算符,以根据员工名称检索员工详细信息。
1 | MATCH (emp:Employee) |
使用WHERE子句创建关系
在Neo4J CQL中,我们可以以不同的方式创建拖曳节点之间的关系。
创建两个现有节点之间的关系
一次创建两个节点和它们之间的关系
使用WHERE子句创建两个现有节点之间的关系
我们已经讨论了前两章中的前两种方法。 现在我们将在本章中讨论“使用WHERE子句创建两个现有节点之间的关系”。
1 | MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>) |
语法说明:
| S.No. | 语法元素 |
|---|---|
| 1 | MATCH,WHERE,CREATE |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 |
例如: 此示例演示如何使用WHERE子句创建两个现有节点之间的关系。
步骤1 -打开Neo4J数据浏览器
步骤2 -在数据浏览器上键入以下命令,以验证我们的Neo4J数据库中是否存在所需的客户节点。
键入以下命令以创建客户和CreditCard节点之间的关系。1
2
3
MATCH (cust:Customer) RETURN cust.id,cust.name,cust.dob输入以下查看两个节点之间的关系:1
2
3
MATCH (cust:Customer),(cc:CreditCard) WHERE cust.id = "1001" AND cc.id= "5001" CREATE (cust)-[r:DO_SHOPPING_WITH{shopdate:"12/12/2014",price:55000}]->(cc) RETURN r-----------------1
2
3
MATCH (cust:Customer),(cc:CreditCard) WHERE cust.id = "1001" AND cc.id= "5001" return cust,cc
DELETE删除
Neo4j使用CQL DELETE子句 删除节点。 删除节点及相关节点和关系。 我们将在本章中讨论如何删除一个节点。 我们将在下一章讨论如何删除节点和相关的节点和关系。
删除节点 -
可以从数据库永久删除节点及其关联的属性。 ###### DELETE节点子句语法
1
2
3
DELETE
注意 -
我们应该使用逗号(,)运算符来分隔节点名。
例如: 此示例演示如何从数据库中永久删除节点。
步骤1 - 打开Neo4j数据浏览器。
步骤2 - 在数据浏览器上键入以下命令 1
2
3
MATCH (e: Employee) RETURN e
MATCH (e: 'Employee') RETURN e
MATCH (e: "Employee") RETURN e
MATCH (e: Employee) RETURN e
所有三个命令都相同,我们可以选择这些命令中的任何一个。
删除命令
1 |
|
DELETE节点和关系子句语法
1 |
|
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1 | DELETE | 它是一个Neo4j CQL关键字。 |
| 2 | 它是用于创建关系 |
|
| 3 | 它是用于创建关系 |
|
| 4 | 它是一个关系名称,它在 |
注意 -
我们应该使用逗号(,)运算符来分隔节点名称和关系名称。
例如: 此示例演示如何从数据库永久删除节点及其关联节点和关系。
1
2
3
MATCH (cc:CreditCard)-[r]-(c:Customer)RETURN r
1 |
|
现在检查DELETE操作是否成功完成。 1
2
3
MATCH (cc:CreditCard)-[r]-(c:Customer) RETURN r
REMOVE删除
有时基于我们的客户端要求,我们需要向现有节点或关系添加或删除属性。
我们使用Neo4j CQL SET子句向现有节点或关系添加新属性。
我们使用Neo4j CQL REMOVE子句来删除节点或关系的现有属性。
Neo4j CQL REMOVE命令用于
- 删除节点或关系的标签
- 删除节点或关系的属性
Neo4j CQL DELETE和REMOVE命令之间的主要区别 - DELETE操作用于删除节点和关联关系。 - REMOVE操作用于删除标签和属性。
Neo4j CQL DELETE和REMOVE命令之间的相似性 - 这两个命令不应单独使用。 - 两个命令都应该与MATCH命令一起使用。
删除节点/关系的属性
我们可以使用相同的语法从数据库中永久删除节点或关系的属性或属性列表。
REMOVE属性子句语法
1 |
|
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1. | REMOVE | 它是一个Neo4j CQL关键字。 |
| 2. | 它是一个属性列表,用于永久性地从节点或关系中删除它。 |
<属性名称列表>语法
1 |
|
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1. | 它是节点的名称。 | |
| 2. | 它是节点的属性名称。 |
注意
- 我们应该使用逗号(,)运算符来分隔标签名称列表。
- 我们应该使用dot(。)运算符来分隔节点名称和标签名称。
例如: 此示例演示如何创建节点并从数据库中永久删除此节点的属性。
1
2
3
CREATE (book:Book {id:122,title:"Neo4j Tutorial",pages:340,price:250})1
2
3
CREATE TABLE BOOK( id number, title varchar2(20), pages number, price number ); INSERT INTO BOOK VALUES (122,'Neo4j Tutorial',340,250);1
2
3
MATCH (book { id:122 }) REMOVE book.price RETURN book1
2
3
ALTER TABLE BOOK REMOVE COLUMN PRICE; SELECT * FROM BOOK WHERE ID = 122;
有时基于客户端要求,我们需要删除一些现有的属性到节点或关系。
我们需要使用REMOVE子句来删除一个属性或一组属性。
例如
此示例演示如何从数据库中永久删除现有节点的属性。 1
2
3
MATCH (dc:DebitCard) RETURN dc
1 |
|
删除节点/关系的标签
我们可以使用相同的语法从数据库中永久删除节点或关系的标签或标签列表。
###### REMOVE一个Label子句语法: REMOVE
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1. | REMOVE | 它是一个Neo4j CQL关键字。 |
| 2. | 它是一个标签列表,用于永久性地从节点或关系中删除它。 |
SET子句
有时,根据我们的客户端要求,我们需要向现有节点或关系添加新属性。
要做到这一点,Neo4j CQL 提供了一个SET子句。
Neo4j CQL 已提供 SET 子句来执行以下操作。 -
向现有节点或关系添加新属性 - 添加或更新属性值 ##### SET子句语法
1
2
3
SET
<属性名称列表>语法:
1 |
|
语法说明:
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1. | 这是一个节点的标签名称。 | |
| 2. | 它是一个节点的属性名。 |
我们应该使用逗号(,)运算符来分隔属性名列表。
示例:演示如何向现有 DebitCard 节点添加新属性。
步骤1 -打开 Neo4j 数据浏览器
步骤2 -在数据浏览器上键入以下命令 1
2
3
MATCH (book:Book) RETURN book
1 |
|
ORDER BY排序
Neo4j CQL ORDER BY子句 Neo4j CQL在MATCH命令中提供了“ORDER BY”子句,对MATCH查询返回的结果进行排序。
我们可以按升序或降序对行进行排序。
默认情况下,它按升序对行进行排序。
如果我们要按降序对它们进行排序,我们需要使用DESC子句。 1
2
3
ORDER BY [DESC]
1
2
3
., ., .... .
| S.No. | 语法元素 | 描述 |
|---|---|---|
| 1. | 它是节点的标签名称。 | |
| 2. | 它是节点的属性名称。 |
注意 -
我们应该使用逗号(,)运算符来分隔属性名列表。
例如: 此示例演示如何按照升序排序“员工名称”结果。
1
2
3
MATCH (emp:Employee) RETURN emp.empid,emp.name,emp.salary,emp.deptno
1 |
|
此示例演示如何按照员工名称按降序使用排序结果。
1
2
3
MATCH (emp:Employee) RETURN emp.empid,emp.name,emp.salary,emp.deptno
1 |
|
UNION合并
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
- UNION
- UNION ALL
UNION子句
它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
限制:
结果列类型和来自两组结果的名称必须匹配,这意味着列名称应该相同,列的数据类型应该相同。
UNION子句语法
1 |
|
MATCH (cc:CreditCard) RETURN cc 1
2
3
4
5
6
7
###### 借记卡数据的节点
第1步 -打开Neo4j的数据浏览器
第2步 -在数据浏览器的美元提示符处键入以下命令。1
2
3
4
5
我们将利用这些数据来解释的Neo4j CQL UNION与实例的使用
本例说明:如果UNION子句的这两个查询确实有相同的名称或相同的数据类型及其列会发生什么。1
2
3
4
5
6
7
8
9
10
11
12
13
这表明,这两个查询应具有相同的列名。
首先查询有:cc.id,cc.number。
第二个查询有:dc.id,dc.number。
这里既有信用卡式和借记卡具有相同的属性名:身份证和号码,但他们有不同的节点名称前缀。这就是为什么UNION命令显示此错误消息。为了避免这种错误,Neo4j的CQL提供“AS”子句。
像CQL,CQL Neo4j的“AS”子句用于给一些别名。
**此示例演示如何使用UNION子句从两个节点检索数据。**1
2
3
4
5
6
7
8
9
10
11
12
13
在这里,因为UNION子句过滤它们,我们可以看到该命令返回9行没有重复的行。
------
##### UNION ALL子句
它结合并返回两个结果集的所有行成一个单一的结果集。它还返回由两个节点重复行。
###### 限制
###### UNION ALL子句语法1
2
3
4
5
> 注意 - 如果这两个查询不返回相同的列名和数据类型,那么它抛出一个错误。 在本章中,我们将采取一个银行应用程序的节点:信用卡式和借记卡解释UNION子句
##### 信用卡式节点数据1
2
3
##### 借记卡数据的节点1
2
3
4
5
我们将利用这些数据来解释的Neo4j CQL UNION与实例的使用
**例子** 本例说明:如果UNION子句的这两个查询确实有相同的名称或相同的数据类型及其列会发生什么。1
2
3
4
5
6
7
8
9
10
11
12
13
** 在这里,我们可以观察到这个命令返回10行,因为与UNION ALL子句不过滤它们重复行。如果我们使用UNION子句,它将返回只有9行。详情请参阅UNION子句章节进行检查。**
**UNION 和 UNION ALL的区别: UNION联合,过滤重复。 UNION ALL 联合 ,不过滤重复**
------
##### LIMIT和SKIP子句
Neo4j CQL已提供“LIMIT”子句来过滤或限制查询返回的行数。 它修剪CQL查询结果集底部的结果。
如果我们要修整CQL查询结果集顶部的结果,那么我们应该使用CQL SKIP子句。 请参考本章的下一节CQL SKIP子句。1
2
3
4
5
6
7
8
| S.No. | 语法元素 | 描述 |
| ----- | -------- | ------------------------- |
| 1。 | LIMIT | 它是一个Neo4j CQL关键字。 |
| 2。 | | 它是一个跨值。 |
本示例演示如何使用CQL LIMIT子句减少MATCH + RETURN查询返回的记录数。1
2
3
**做限制:**1
2
3
4
5
6
7
8
9
10
11
它只返回Top的两个结果,因为我们定义了limit = 2。这意味着前两行。
##### **SKIP子句**
Neo4j CQL已提供“SKIP”子句来过滤或限制查询返回的行数。 它修整了CQL查询结果集顶部的结果。
如果我们要从CQL查询结果集底部修整结果,那么我们应该使用CQL LIMIT子句。 请参阅本章的上一节CQL LIMIT子句。
###### SKIP子句语法:1
2
3
4
5
|S.No.| 语法元素| 描述| |-----|-----| |1。| SKIP| 它是一个Neo4j CQL关键字。| |2。| | 它是一个间隔值。|
**例如:** 此示例演示如何使用CQL SKIP子句减少MATCH + RETURN查询返回的记录数。 在带有SKIP子句的数据浏览器上键入以下命令1
2
3
4
5
6
7
8
9
10
11
12
skip跳过两个节点,因此我们定义了skip = 2。这意味着**最后两行。**
##### 合并
Neo4j使用CQL MERGE命令 -
- 创建节点,关系和属性
- 为从数据库检索数据
MERGE命令是CREATE命令和MATCH命令的组合。1
2
3
4
5
6
7
MERGE命令在图中搜索给定模式,如果存在,则返回结果
如果它不存在于图中,则它创建新的节点/关系并返回结果。
###### MERGE语法1
2
3
4
5
6
7
8
9
|S.No.| 语法元素| 描述| |-----|-----| |1。| MERGE| 它是一个Neo4j CQL关键字。| |2。| | 它是一个间隔值。| |2。| | 它是节点或关系的标签名称。| |2。| <property_name>| 它是节点或关系的属性名称| |2。| <property_value>| 它是节点或关系的属性值。| |2。| :| 使用colon(:)运算符来分隔节点或关系的属性名称和值。|
###### CREATE示例
例子 此示例通过使用CREATE,MATCH和RETURN命令创建Google+个人资料,执行上述所有操作。
**操作(1):创建具有属性:Id,Name的Profile节点**1
2
3
**操作(2):创建具有相同属性的同一个Profile节点:Id,Name。**1
2
3
**操作(3):检索所有Profile节点详细信息并观察结果。**1
2
3
4
5
6
7
8
9
10
11
如果我们观察到上面的查询结果,它显示2行重复的值。
CQL CREATE命令检查此节点是否可用,它只是在数据库中创建新节点。 通过观察这些结果,我们可以说CREATE命令总是向数据库添加新的节点。
##### MERGE示例
此示例通过使用MERGE和RETURN命令创建Google+个人资料,执行相同的上述操作。
###### 操作(1):创建具有属性:Id,Name的Profile节点1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
如果我们观察上面的查询结果,它只显示一行,因为CQL MERGE命令检查该节点在数据库中是否可用。 如果它不存在,它创建新节点。 否则,它不创建新的。
通过观察这些结果,我们可以说,CQL MERGE命令将新的节点添加到数据库,只有当它不存在。
##### NULL值
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
让我们用一个例子来看这个。
此示例演示CREATE命令如何将NULL值设置为未定义属性。 如何检索没有NULL行的节点的所有行。1
2
3
创建任何属性到Employee节点。1
2
3
观察这些结果,则以前的CREATE命令通过将其所有属性值设置为NULL来插入Employee节点。1
2
3
观察这些结果,它不返回NULL值行,因为我们提供了一个WHERE子句来过滤该行,即Id属性不应该包含NULL值。1
2
3
4
5
6
7
8
9
10
11
观察这些结果,它只返回NULL值行,因为我们提供了一个WHERE子句来检查ID值为NULL。
------
##### IN操作符
与SQL一样,Neo4j CQL提供了一个IN运算符,以便为CQL命令提供值的集合。
###### IN操作符语法1
2
3
4
5
6
7
8
9
10
11
12
语法说明:
| S.No. | 语法元素 | 描述 |
| ----- | -------- | ------------------------------------- |
| 1。 | IN | 它是一个Neo4j CQL关键字。 |
| 2。 | [ | 它告诉Neo4j CQL,一个值的集合的开始。 |
| 3。 | ] | 它告诉Neo4j CQL,值集合的结束。 |
| 4。 | | 它是由逗号运算符分隔的值的集合。 |
此示例演示如何使用IN运算符检索Employee节点详细信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
此查询仅返回在IN运算符中指定的id匹配的两行。
------
##### 图形字体
我们使用Neo4j数据浏览器来执行和查看Neo4j CQL命令或查询的结果。
Neo4j数据浏览器包含两种视图来显示查询结果 -
- UI查看
- 网格视图
我们将讨论如何在UI视图中更改节点或关系的字体。
当我们在数据浏览器中执行Neo4j CQL RETURN子句时,它会在网格视图或UI视图中显示结果。
默认情况下,Neo4j数据浏览器以小字体显示节点或关系图,并在UI视图中显示默认颜色。 如果我们想要在更大的字体或不同的颜色中查看它们,那么如何增加他们的字体(大小)或如何改变他们的颜色。
------
##### ID属性
在Neo4j中,“Id”是节点和关系的默认内部属性。 这意味着,当我们创建一个新的节点或关系时,Neo4j数据库服务器将为内部使用分配一个数字。 它会自动递增。
**例如**: 此示例演示了Neo4j DB服务器如何为节点分配Id属性以及如何查看此属性值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
以相同的方式,Neo4j数据库服务器为关系分配一个默认Id属性。
- 节点的Id属性的最大值约为35亿。
- Id的最大值关系的属性的大约35亿。
------
##### Caption标题
在Neo4j数据中,当我们在Neo4j DATA浏览器中执行MATCH + RETURN命令以查看UI视图中的数据时,通过使用它们的Id属性显示节点和/或关系结果。 它被称为“CAPTION”的id属性。
我们可以通过使用它的其他属性值来更改节点或关系的CAPTION。、
##### 方向关系
在Neo4j中,两个节点之间的关系是有方向性的。 它们是单向或双向的。
由于Neo4j遵循属性图数据模型,它应该只支持方向关系。 如果我们尝试创建一个没有任何方向的关系,那么Neo4j DB服务器应该抛出一个错误。
在本章中,我们将提供一个例子来证明这一点。
我们使用以下语法来创建两个节点之间的关系。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
这里 -
- 是“From Node”节点详细信息
- 是“到节点”节点详细信息
- relationship-details>是关系详细信息
如果我们观察上面的语法,它使用一个箭头标记:() - []→()。 它表示从左侧节点到右侧节点的方向。
如果我们尝试使用相同的语法,没有箭头标记like() - [] - (),这意味着没有方向的关系。 然后Neo4j DB服务器应该抛出一个错误消息
[========]
### Neo4J CQL - 字符串函数
与SQL一样,Neo4J CQL提供了一组String函数,用于在CQL查询中获取所需的结果。
这里我们将讨论一些重要的和经常使用的功能。
字符串函数列表
|S.No.| 功能 |描述| |-----|---------| |1。| ~~UPPER~~ |它用于将所有字母更改为大写字母。| |2。| ~~LOWER~~ |它用于将所有字母改为小写字母。| |3。 |toupper |它用于将所有字母更改为大写字母。| |4。 |tolower |它用于将所有字母改为小写字母。| |5。| SUBSTRING| 它用于获取给定String的子字符串。| |6。 |REPLACE |它用于替换一个字符串的子字符串。|
##### UPPER
它需要一个字符串作为输入并转换为大写字母。 所有CQL函数应使用“()”括号。
**函数语法**1
2
3
4
5
6
7
8
9
10
11
注意:-
可以是来自Neo4J数据库的节点或关系的属性名称。
**示例-**
此示例演示如何使用CQL UPPER String函数以大写形式检索Employee节点的Ename属性详细信息。
步骤1 -在数据浏览器的美元提示符处键入以下命令。1
2
3
将e.name改成大写(旧版本中已失效)1
2
3
将e.name改成大写(新版本中生效)1
2
3
4
5
##### TOLOWER
它需要一个字符串作为输入并转换为小写字母。 所有CQL函数应使用“()”括号。1
2
3
4
5
6
7
##### SUBSTRING
它接受一个字符串作为输入和两个索引:一个是索引的开始,另一个是索引的结束,并返回从StartInded到EndIndex-1的子字符串。 所有CQL函数应使用“()”括号。
###### 函数的语法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
**注意:-**
在Neo4J CQL中,如果一个字符串包含n个字母,则它的长度为n,索引从0开始,到n-1结束。
是SUBSTRING函数的索引值。
是可选的。 如果我们省略它,那么它返回给定字符串的子串从startIndex到字符串的结尾。
让我们用一个例子来研究一下。
示例-
此示例演示如何检索所有员工详细信息的名称属性的前两个字母。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
它使用SUBSTRING()String函数打印Employee名称的前两个字母。
------
##### **AGGREGATION聚合**
和SQL一样,Neo4j CQL提供了一些在RETURN子句中使用的聚合函数。 它类似于SQL中的GROUP BY子句。
我们可以使用MATCH命令中的RETURN +聚合函数来处理一组节点并返回一些聚合值。
聚合函数列表
|S.No.| 聚集功能| 描述| |---------|------------| |1。| COUNT |它返回由MATCH命令返回的行数。| |2。| MAX |它从MATCH命令返回的一组行返回最大值。| |3。 |MIN |它返回由MATCH命令返回的一组行的最小值。| |4。| SUM| 它返回由MATCH命令返回的所有行的求和值。|| |5。 |AVG |它返回由MATCH命令返回的所有行的平均值。|
###### 计数
它从MATCH子句获取结果,并计算结果中出现的行数,并返回该计数值。 所有CQL函数应使用“()”括号。 ####### 函数语法1
2
3
4
5
6
7
8
9
注意 -
可以是*,节点或关系标签名称或属性名称。
示例-
此示例演示如何使用COUNT(*)函数返回数据库中可用的Employee节点数。1
2
3
4
5
6
7
8
9
------
##### MAX
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找最大值。
###### 函数语法1
2
3
4
5
6
7
##### MIN
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找最小值。
###### 函数语法1
2
3
4
5
6
7
8
9
注意 -
应该是节点或关系的名称。
**示例-**
此示例演示如何从所有员工节点中查找最高和最低工资值1
2
3
4
5
##### AVG
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找平均值。1
2
3
4
5
6
7
##### SUM
它采用一组行和节点或关系的作为输入,并从给定行的give 列中查找求和值。
###### 函数的语法1
2
3
**例子** 此示例演示如何查找所有员工节点的总和平均薪水值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#### 关系函数
Neo4j CQL提供了一组关系函数,以在获取开始节点,结束节点等细节时知道关系的细节。
在这里,我们将讨论一些重要的和经常使用的功能。 关系函数列表
|S.No.| 功能| 描述| |----|-----| |1。| STARTNODE| 它用于知道关系的开始节点。| |2。 |ENDNODE |它用于知道关系的结束节点。| |3。| ID |它用于知道关系的ID。| |4。| TYPE |它用于知道字符串表示中的一个关系的TYPE。|
##### STARTNODE和ENDNODE
它需要一个字符串作为输入并为大写格式, 所有CQL函数应使用“()”括号。
###### 函数语法1
2
3
4
5
6
7
8
9
注意: 可以是来自Neo4j数据库的节点或关系的属性名称。
示例-
此示例演示如何使用CQL STARTNODE关系函数来检索关系的开始节点详细信息。
在关系“ACTION_MOVIES”上执行STARTNODE()函数之前,我们将检查其详细信息1
2
3
4
5
##### ID和TYPE
ID和TYPE关系函数来检索关系的Id和类型详细信息。1
2
3
4
5
6
7
8
9
它使用STARTNODE()关系函数打印关系“ACTION_MOVIES”的开始节点。
**示例-**
此示例演示如何使用CQL ENDNODE关系函数来检索关系的结束节点详细信息。
在关系“ACTION_MOVIES”上执行ENDNODE()函数之前,我们将检查它的详细信息1
2
3
在这里,我们可以观察到关系的结束节点“ACTION_MOVIES”是“YoutubeVideo2”。 让我们检查这个与功能。1
2
3
4
5
6
7
**示例-**
此示例演示如何使用CQL ID和TYPE关系函数来检索关系的Id和类型详细信息。
在关系“ACTION_MOVIES”上执行ID和TYPE函数之前,我们将检查其详细信息1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
[========]
### Neo4j - 数据库备份和恢复
在实时应用程序中,我们应定期备份应用程序数据库,以便在任何故障点恢复到某种工作状态。
此规则适用于RDBMS和无SQL数据库。
在本节中,我们将讨论两个重要的DBA任务。
- 如何备份Neo4j数据库。
- 如何将Neo4j数据库还原到特定的备份。
**注意:-**
这些步骤仅适用于Windows操作系统。 我们应该使用类似的命令在其他操作系统中执行相同的步骤。
##### Neo4j数据库备份
(空)
##### 索引
> Neo4j SQL支持节点或关系属性上的索引,以提高应用程序的性能。 我们可以为具有相同标签名称的所有节点的属性创建索引。 我们可以在MATCH或WHERE或IN运算符上使用这些索引列来改进CQL Command的执行。
###### Neo4J索引操作
- Create Index 创建索引
- Drop Index 丢弃索引 我们将在本章中用示例来讨论这些操作。
###### 创建索引语法:
Neo4j的CQL提供“CREATE INDEX”命令创建的节点或关系的属性索引。
###### 创建索引的语法:1
2
3
4
5
6
7
8
9
10
11
12
13
**注意**:-
冒号(:)运算符用于引用节点或关系标签名称。
上述语法描述它在节点或关系的<label_name>的<property_name>上创建一个新索引。
**示例**-
此示例演示如何在CreditCard节点的number属性上创建INDEX。
步骤1 -在数据浏览器上键入以下命令1
2
3
4
5
6
7
8
9
------
##### Drop Neo4j索引
Neo4j CQL已提供“DROP INDEX”命令删除NODE或Relationship的属性的现有索引。
###### Drop Index语法:1
2
3
4
5
6
7
8
9
10
11
注意:-
冒号(:)运算符用于引用节点或关系标签名称。
上述语法描述它删除在节点或关系的<label_name>的<property_name>上创建的现有索引。
示例-
此示例演示如何删除CreditCard节点的number属性上的INDEX。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
> **创建了索引怎么使用呢?**
------
#### Neo4j CQL - UNIQUE约束
> 在Neo4j数据库中,CQL CREATE命令始终创建新的节点或关系,这意味着即使您使用相同的值,它也会插入一个新行。 根据我们对某些节点或关系的应用需求,我们必须避免这种重复。 然后我们不能直接得到这个。 我们应该使用一些数据库约束来创建节点或关系的一个或多个属性的规则。 像SQL一样,Neo4j数据库也支持对NODE或Relationship的属性的UNIQUE约束
UNIQUE约束的优点
- 避免重复记录。
- 强制执行数据完整性规则。
Neo4j CQL UNIQUE约束操作
- 创建UNIQUE约束
- 丢弃UNIQUE约束。
创建UNIQUE约束 Neo4j CQL已提供“CREATE CONSTRAINT”命令,以在NODE或关系的属性上创建唯一约束。
创建唯一约束语法1
2
3
4
5
6
7
语法说明:
|S.No.| 语法元素| 描述 |---------|----------| |1。| CREATE CONSTRAINT ON| 它是一个Neo4j CQL关键字。| |2。| <label_name>| 它是节点或关系的标签名称。|| |3。| ASSERT |它是一个Neo4j CQL关键字。| |4。| <property_name> |它是节点或关系的属性名称。| |5。| IS UNIQUE |它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。|
此示例演示如何在CreditCard节点的number属性上创建UNIQUE约束。1
2
3
4
5
6
7
8
9
10
11
12
13
这表明,创建具有相同CreditCard.number的重复节点是不可能的,因为它有唯一约束
#### Neo4j CQL - DROP UNIQUE
我们已经讨论了使用前一章中的示例创建UNIQUE约束操作。 现在我们将讨论使用本章中的示例删除UNIQUE约束操作。
##### 删除UNIQUE约束
Neo4j CQL提供了“DROP CONSTRAINT”命令,以从NODE或Relationship的属性中删除现有的Unique约束。
###### 删除UNIQUE约束语法:1
2
3
4
5
6
7
8
9
10
11
语法说明
|S.No.| 语法元素| 描述| |---|----| |1。| DROP CONSTRAINT ON |它是一个Neo4j CQL关键字。| |2。 |<label_name> |它是节点或关系的标签名称。| |3。| ASSERT |它是一个Neo4j CQL关键字。| |4。| <property_name> |它是节点或关系的属性名称。| |5。| IS UNIQUE |它是一个Neo4j CQL关键字,通知Neo4j数据库服务器创建一个唯一约束。|
**注意 -**
上述语法描述它从节点或关系的<label_name>的<property_name>中删除唯一约束。
**示例** 此示例演示如何从CreditCard节点的number属性删除现有UNIQUE约束。1
2
3
删除UNIQUE约束1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#### Neo4j - Java简介
Neo4j提供JAVA API以编程方式执行所有数据库操作。
它支持两种类型的API:
- Neo4j的原生的Java API
- Neo4j Cypher Java API Neo4j原生Java API是一种低级别的纯JAVA API,用于执行数据库操作。 Neo4j Cypher Java API是简单而强大的JAVA API,用于执行所有CQL命令以执行数据库操作。
#### 原生Java API
Neo4j原生Java API示例 此示例演示如何在Eclipse IDE中开发Java应用程序以开发和测试Neo4j原生ava API示例
- 第1步 -在同一个Java项目中创建一个Java程序 现在开始编写Neo4j Java API编码以执行Neo4j DB操作
- 第2步 -创建Neo4j数据库1
2
3
4
5
它在指定的路径为我们创建一个Schema / Database,如下所示。这类似于Oracle SQL的“CREATE DATABASE”命令。
- 第3步 -启动Neo4j数据库事务以提交我们的更改
tx.success(); } 1
2
3
所以对于你的Java程序源代码看起来像
tx.success(); }
} } 1
2
3
- 第4步 -要创建节点,我们需要标签名称。 通过实现Neo4j Java API“Label”接口创建一个枚举。1
2
3
- 第5步 -创建节点并为其设置属性 创建两个节点1
2
3
设置属性
scalaNode.setProperty("TutorialID", "SCALA001");
scalaNode.setProperty("Title", "Learn Scala");
scalaNode.setProperty("NoOfChapters", "20");
scalaNode.setProperty("Status", "Completed"); 1
2
3
- 第6步 -要创建关系,我们需要关系类型。 通过实现Neo4j“关系类型”创建枚举。1
2
3
- 第7步 -创建节点之间的关系并设置它的属性。 创建从Java节点到Scala节点的关系1
2
3
将属性设置为此关系1
2
3
- 第8步 -最终源代码。
public class Neo4jJavaAPIDBOperation { public static void main(String[] args) { GraphDatabaseFactory dbFactory = new GraphDatabaseFactory(); GraphDatabaseService db= dbFactory.newEmbeddedDatabase("C:/TPNeo4jDB"); try (Transaction tx = db.beginTx()) {
Node javaNode = db.createNode(Tutorials.JAVA);
javaNode.setProperty("TutorialID", "JAVA001");
javaNode.setProperty("Title", "Learn Java");
javaNode.setProperty("NoOfChapters", "25");
javaNode.setProperty("Status", "Completed");
Node scalaNode = db.createNode(Tutorials.SCALA);
scalaNode.setProperty("TutorialID", "SCALA001");
scalaNode.setProperty("Title", "Learn Scala");
scalaNode.setProperty("NoOfChapters", "20");
scalaNode.setProperty("Status", "Completed");
Relationship relationship = javaNode.createRelationshipTo
(scalaNode,TutorialRelationships.JVM_LANGIAGES);
relationship.setProperty("Id","1234");
relationship.setProperty("OOPS","YES");
relationship.setProperty("FP","YES");
tx.success();
}
System.out.println("Done successfully");} } 1
2
3
4
5
- 第9步 -在执行此Java程序之前,检查您的Neo4j是否处于关闭模式。 如果没有,请点击“停止”按钮展开它。
- 第10步 -执行Java程序并在Eclipse IDE控制台中观察输出。 一旦此数据库成功启动,通过单击“http:// localhost:7474”链接访问Neo4j浏览器来观察我们的数据。
- 第11步 -在Neo4j数据浏览器的$ prompt下键入以下命令1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
注意 -
如果我们的Neo4j服务器通过引用我们新创建的数据库启动和运行,那么我们不能执行我们的程序,因为服务器已经锁定了这个数据库。
所以当我们执行我们以前的程序时,我们会得到一些错误堆栈跟踪
java.io.IOException:C:\TPNeo4jDB\lock because another process already holds the lock.
为了避免这个问题,首先停止我们的服务器,然后执行程序。
因为默认情况下Neo4j DB Server一次只接受一个锁。 在实时应用程序中,Ne04J DBA人员将更新数据库属性以允许一次允许一些数量的锁。
------
#### Neo4j Cypher - API示例
本章中讨论Neo4j Cypher Java API。 如果你观察到Neo4j Native Java API方法,开发大型应用程序是非常乏味和麻烦的。 所以为了避免这种复杂性,Neo4j引入了另一组Java API。
此Java API用于直接执行Neo4j CQL命令。 它类似于JDBC API直接执行SQL命令。
##### Neo4j Cypher Java API示例
> 本示例演示如何在Eclipse IDE中开发Java应用程序,以开发和测试Neo4j Cypher Java API示例
- 第1步 创建Java类JavaNeo4jCQLRetrivalTest
现在开始编写Neo4j Java API编码以执行Neo4j DB操作
- 第2步 -创建Neo4j数据库1
2
3
4
5
它在指定的路径为我们创建一个Schema / Database,如下所示。这类似于Oracle SQL的“CREATE DATABASE”命令。
- 第3步 -创建Neo4j Cypher执行引擎。它用于在Java应用程序中执行Neo4j CQL命令。1
2
3
- 第4步 - 通过使用Neo4j Cypher Execution Engine,执行Neo4j CQL Command以检索CQL MATCH命令的结果。1
2
3
- 第5步 -获取CQL命令结果的字符串,以在控制台中打印结果。1
2
3
- 第6步 -最终源代码。
import org.neo4j.cypher.javacompat.ExecutionEngine; import org.neo4j.cypher.javacompat.ExecutionResult; import org.neo4j.graphdb.GraphDatabaseService; import org.neo4j.graphdb.factory.GraphDatabaseFactory;
public class JavaNeo4jCQLRetrivalTest {
public static void main(String[] args) { GraphDatabaseFactory graphDbFactory = new GraphDatabaseFactory();
GraphDatabaseService graphDb = graphDbFactory.newEmbeddedDatabase("C:/TPNeo4jDB");
ExecutionEngine execEngine = new ExecutionEngine(graphDb);
ExecutionResult execResult = execEngine.execute("MATCH (java:JAVA) RETURN java");
String results = execResult.dumpToString();
System.out.println(results);} } 1
2
3
- 第7步 -在Neo4j数据浏览器的$ prompt下输入以下命令1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
注意 -
像这样,我们可以使用Neo4j JAVA API执行任何CQL命令。
如果我们的Neo4j服务器通过引用我们新创建的数据库启动和运行,那么我们不能执行我们的程序,因为服务器已经锁定了这个数据库。
所以当我们执行我们以前的程序时,我们会得到一些错误堆栈跟踪
java.io.IOException: Couldn't lock lock file C:\TPNeo4jDB\lock because another process already holds the lock.
为了避免这个问题,首先停止我们的服务器,然后执行程序。
因为默认情况下Neo4j DB Server一次只接受一个锁。 在实时应用程序中,Ne04J DBA人员将更新数据库属性以允许一次允许一些数量的锁。
[========]
#### Spring DATA Neo4J - 简介
#### Spring DATA Neo4J - 环境
在本章中,我们将讨论如何在Eclipse IDE中设置Maven Java项目,以使用Spring DATA Neo4j模块开发Spring Framework应用程序。
- 第1步 - 在Eclipse IDE中创建Maven项目
- 第2步-在Eclipse IDE中打开pom.xml文件,并添加以下主要依赖关系
Spring DATA Neo4j模块Jar文件1
2
3
Neo4j Jar文件,由Spring DATA Neo4j模块Jar文件内部使用1
2
3
Java事务API jar文件,由Spring DATA Neo4j模块Jar文件内部使用1
2
3
Java验证API jar文件,由Spring DATA Neo4j模块Jar文件内部使用1
2
3
第3步-完成pom.xml文件
<dependency>
<groupId> org.neo4j </groupId>
<artifactId> neo4j-kernel </artifactId>
<version> 2.1.3 </version>
</dependency>
<dependency>
<groupId> javax.transaction </groupId>
<artifactId> jta </artifactId>
<version> 1.1 </version>
</dependency>
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
<version>1.0.0.GA</version>
</dependency>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#### Spring DATA Neo4j - 示例
> 我们将讨论如何开发一个 Spring 框架项目来使用 Neo4j 数据库。
##### Spring DATA Neo4j 模块注释
我们将使用以下 Spring Framework 注释来开发此应用程序。
|S.No.| Spring DATA Neo4j注释 |用法 |--------|----------| |1| @GraphEntity |定义域类Neo4j Entity| |2| @GraphID |定义节点或关系id| |3| @GraphProperty |定义节点或关系属性| 在开发应用程序之前,请参考“Neo4j Spring DATA环境设置”一章来设置 Maven Eclipse IDE 项目。
(空)
------
### 常见CQL语句
CREATE (emp:Employee) CREATE(节点名:标签名)
CREATE (dept:Dept { deptno:10,dname:"Accounting",location:"Hyderabad" }) 创建一个带有属性的标签名
CREATE (fb1:FaceBookProfile1)-[like:LIKES]→(fb2:FaceBookProfile2) 新增关系
查询:
MATCH (n:hx/sor_config) RETURN n LIMIT 25
查询sor_config中id前25
MATCH (dept:Dept) RETURN dept.deptno 查询Dept
MATCH (n:hx/sor_config) WHERE n.name="ruleset3" RETURN n
条件查询
MATCH
(p1:hx/sor_config{name:"手术程序"}),(p2:hx/sor_config{name:"structured_situation"}),
p=shortestpath((p1)-[*..10]->(p2)) RETURN p 查询p1到p2的最短路径
MATCH (n:hx/sor_config{name:"手术名称"})-[r*..1]-(m)
return n,r,m 查询某个节点的直接关系的其他节点
删除:
MATCH (e: Employee) DELETE e 删除标签
match (n:FaceBookProfile1)-[r]-(m:FaceBookProfile2) delete r 删除关系
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r 清空数据库
MATCH (n:hx/sor_config{name:"有无袖式成型切除"}) DETACH
DELETE n 删除某一节点及其所有关系
修改:
MATCH (n:Empty) SET n.atm_pin = 358 RETURN n 1
2
3
### Python代码
##连接neo4j数据库,输入地址、用户名、密码 graph = Graph('http://localhost:7474',username='neo4j',password='password')
##创建结点 test_node_1 = Node('ru_yi_zhuan',name='皇帝') test_node_2 = Node('ru_yi_zhuan',name='皇后') test_node_3 = Node('ru_yi_zhuan',name='公主') graph.create(test_node_1) graph.create(test_node_2) graph.create(test_node_3)
##创建关系 #分别建立了test_node_1指向test_node_2和test_node_2指向test_node_1两条关系,关系的类型为"丈夫、妻子",两条关系都有属性count,且值为1。 node_1_zhangfu_node_1 = Relationship(test_node_1,'丈夫',test_node_2) node_1_zhangfu_node_1['count'] = 1 node_2_qizi_node_1 = Relationship(test_node_2,'妻子',test_node_1) node_2_munv_node_1 = Relationship(test_node_2,'母女',test_node_3)
node_2_qizi_node_1['count'] = 1
graph.create(node_1_zhangfu_node_1) graph.create(node_2_qizi_node_1) graph.create(node_2_munv_node_1) ```

